Our new paper gives very simple algorithms that promise "multivalid" conformal prediction sets for exchangable data. This means they are valid not just marginally, but also conditionally on (intersecting!) group membership, and in a threshold calibrated manner. I'll explain!

Instead of making point predictions, we can quantify uncertainty by producing "prediction sets" --- sets of labels that contain the true label with (say) 90% probability. The problem is, in a k label prediction problem, there are $2^k$ prediction sets. The curse of dimensionality!

One of the great ideas of conformal prediction is that if we can find a good "non-conformity score" s(x,y) telling us how unusual a label y seems for features x, we can focus on a 1-parameter family of prediction sets $P(x, t) = \{y : s(x,y) < t\}$. Now the problem is just to find $t$.
The usual recipe in split conformal prediction is to use a holdout set of points (x,y) to find a $t$ such that $\Pr[s(x,y) \leq t] = 0.9$. Then over the randomness of new examples (x,y), we have that $\Pr[y \in P(x,t)] = 0.9$. This is a -marginal- guarantee: the randomness is over x and y.
Suppose we have a bunch of groups (subsets of the feature space) g that we think are prediction-relevant? g could record e.g. demographic or other attributes of people. We might want to promise $\Pr[y \in P(x,t) | x \in g] = 0.9$. Vanilla split conformal doesn't promise this.

If the groups g are disjoint, you could use a different threshold $t_g$ for each group --- but what if a single example can be a member of multiple groups? You can be conservative and use the largest threshold $t_g$ among all groups g that x is a member of, but this will over-cover.
The first insight here is that it no longer suffices to find a single threshold $t$ --- we need to find a function f mapping examples to thresholds, and to consider prediction sets $P(x,f(x)) =\{y : s(x,y) < f(x)\}$. The problem is to use a calibration set to train the function f.
Our first algorithm is super simple and given any set of (intersecting!) groups G, trains f such that for every $g \in G$, we have that for new examples, $\Pr[y \in P(x,f(x))|g\in G] = 0.9$. How? f just minimizes pinball loss over linear combinations of group indicator functions $g \in G$.

Now that we are using different thresholds f(x) for different x, you might worry that the threshold f(x) itself is correlated with coverage. To make sure its not, we can also ask for threshold calibration: $\Pr[y \in P(x,f(x)) | x \in g, f(x) = t] = 0.9$ for all $g \in G$ and all t.
Our second algorithm trains f so that it has both group conditional and threshold calibrated coverage - what we call "full multivalid" coverage. It is also simple: It iteratively finds pairs $(g,t)$ on which multivalid coverage is violated empirically, and corrects the violations.

This is the batch analogue of what we did in our NeurIPS 2022 paper in the sequential setting, which I wrote about here: https://aaronsadventures.blogspot.com/2022/06/practical-robust-and-equitable.html The sequential setting is more difficult in many respects (no need to assume exchangable data!) but it requires labels at test time. Our new algorithms don't.
Both algorithms are very performant, taking a couple
of seconds to train on thousands of points. Our first algorithm gets nearly perfect group conditional coverage on real datasets,
and our second is never off by more than 1%, both improving significantly on baselines.
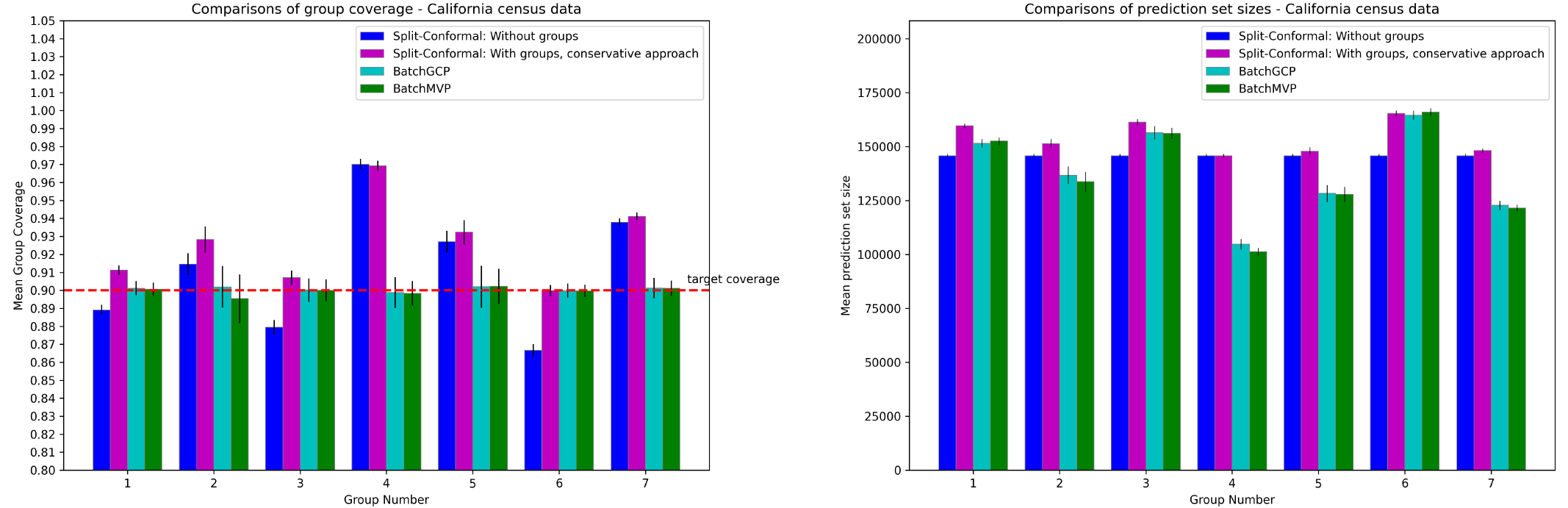
Our second algorithm gets better threshold calibration than our first (and compared to baselines), as expected. But perhaps surprisingly, our first algorithm performs quite well on calibration tests
--- significantly beating
baselines --- despite
no formal calibration guarantees.

Our techniques come from the algorithmic fairness literature --- we train f to satisfy quantile analogues of multicalibration and multi-accuracy. If you haven't
been paying attention to algorithmic fairness, maybe
you should start
--- there is interesting stuff
going on there! Check out e.g. the Simons Collaboration on Algorithmic Fairness
This is joint work with the excellent Chris Jung, Georgy Noarov, and Ramya Ramalingam.

Our paper is here: https://arxiv.org/abs/2209.15145 and our code is here: https://github.com/ProgBelarus/BatchMultivalidConformal